Instant‑Fold: In-Context Imitation Learning for Deformable Object Manipulation
Under Review
Given a single human demonstration as a prompt, Instant‑Fold infers and executes diverse manipulation modes directly from the demonstration without requiring gradient updates.
Abstract
Deformable object manipulation (DOM) is challenging due to high-dimensional, partially observable states that evolve through long-horizon, topology-changing interactions with multiple valid manipulation modes. We introduce Instant‑Fold, an in-context imitation learning framework for DOM. Given a single human demonstration, our policy infers and executes diverse manipulation modes directly from the demonstration—including variations in spatial execution and ordering—without requiring gradient updates. Our approach first learns deformation-aware visual representations via temporal contrastive pretraining, after which a flow-matching transformer policy conditioned on the demonstration predicts actions to execute the intended manipulation mode. Trained entirely in simulation, Instant‑Fold generalizes across diverse folding modes and transfers zero-shot to real-world settings without additional data collection or finetuning.
Overview
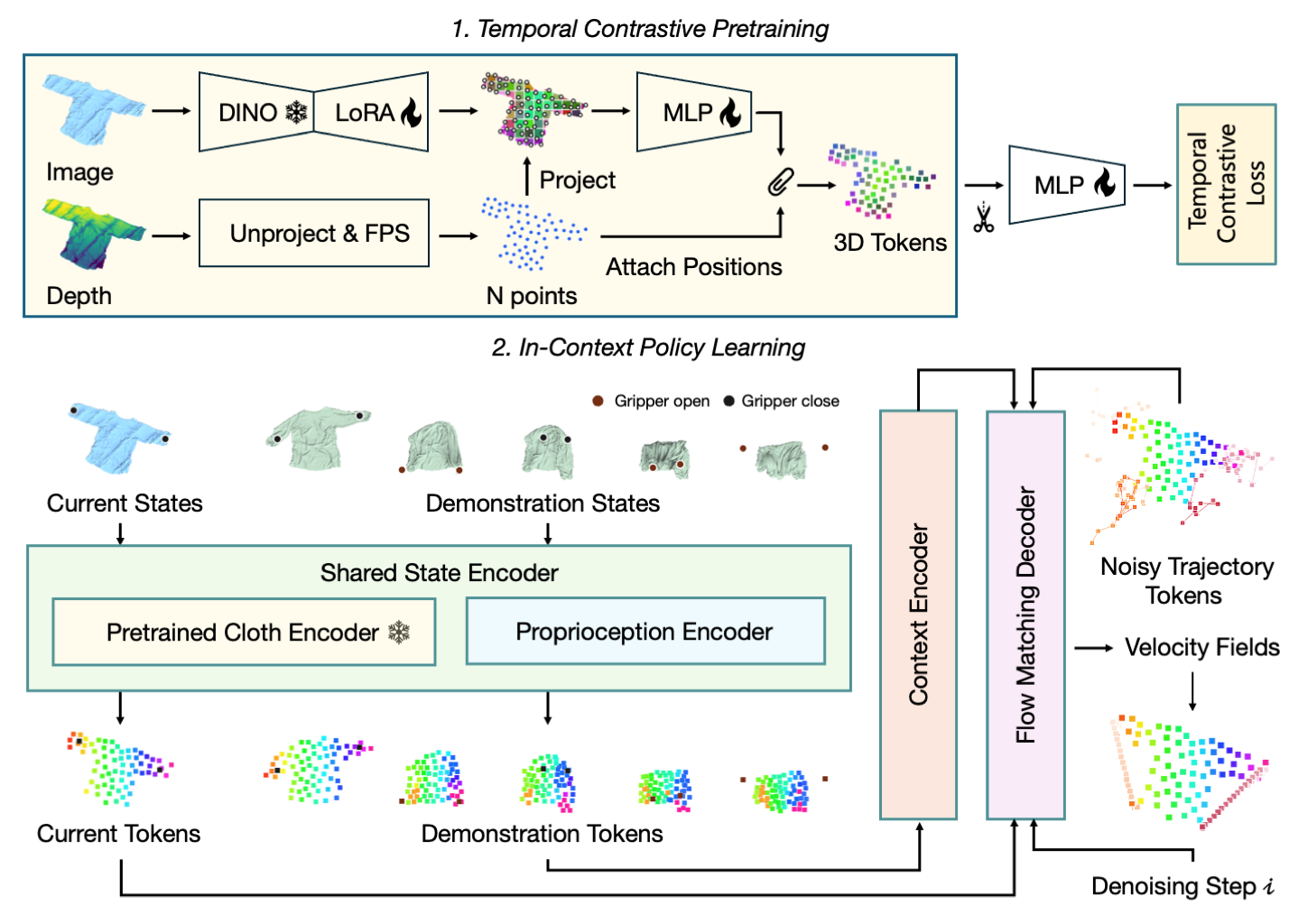
Overview of Instant‑Fold: (1) We first pretrain a deformation-aware tokenizer with temporal contrastive supervision, lifting masked RGB-D observations into geo-semantic 3D cloth tokens. (2) During policy learning, the shared encoders tokenize both the demonstration and current observations, aggregate dense spatio-temporal demonstration context, and condition a flow-matching denoising transformer to reconstruct clean dual-arm action trajectories from noise.
Temporal Constrative Pretraining
We introduce a soft-weighted supervised contrastive objective to pretrain deformation-aware visual representation in simulation.
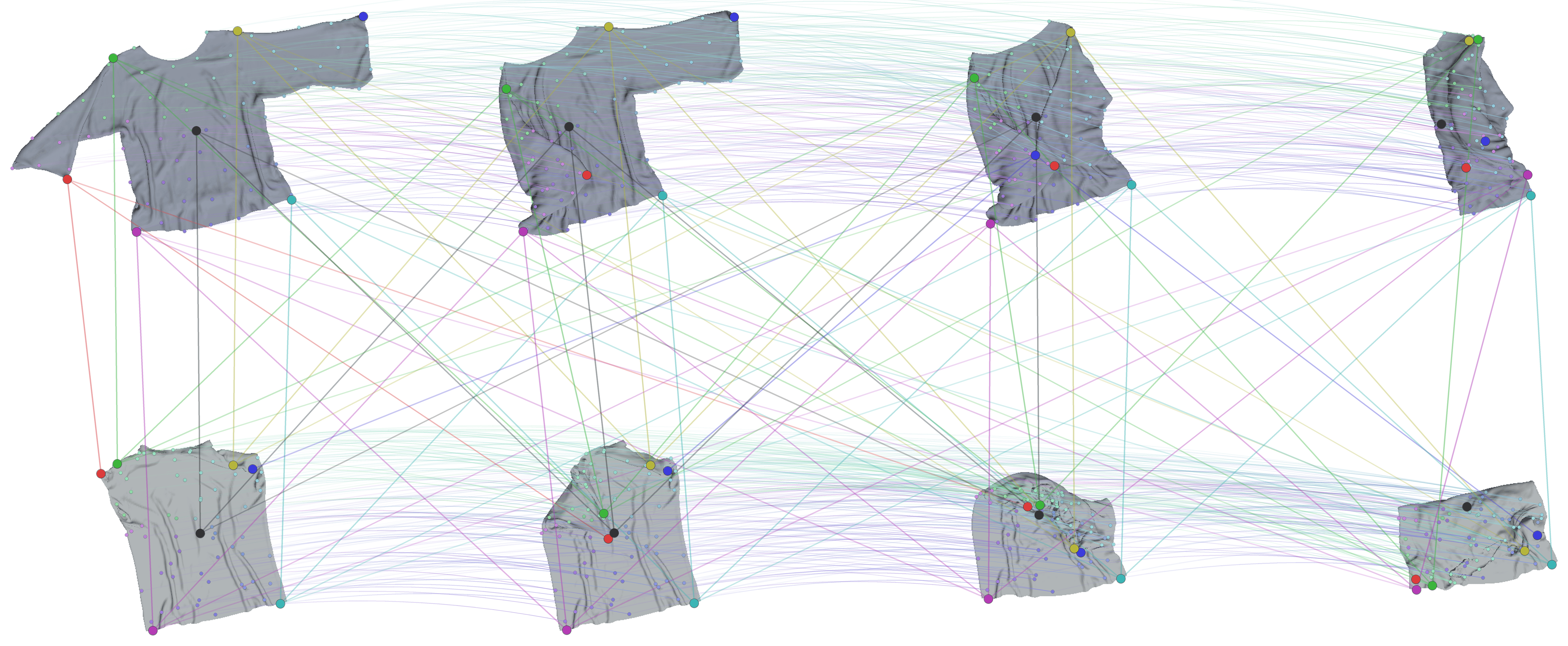
As a result, our visual encoder produces temporally consistent and spatially coherent representation for downstream manipulation.

 Ours UniGarment
Ours UniGarment 
 Ours UniGarment
Ours UniGarment In-Context Policy Learning
During policy learning, the model performs demonstration-conditioned flow matching using pretrained visual tokens.
Simulation Rollouts on Unseen Meshes
We show different simulation rollouts for folding modes both seen and unseen during training.
Fold both sleeves down to the bottom corners, then fold the shoulders down to the hem. Do the left sleeve first.

Zero-Shot Sim2Real with Human Demonstration
Our policy transfers zero-shot to the real world without any real-world data collection or fine-tuning and instantly executes the intended folding strategy from a single human demonstration without requiring robot demonstrations.
More Examples
Failure Modes
Kinematic Failure
The robot reaches the limits of its workspace or a kinematic singularity, preventing it from continuing to execute the policy. This can be addressed by incorporating kinematic modeling during data generation or by including data that teaches the robot to rearrange the cloth to satisfy kinematic constraints.